Fraud Detection Single Case
Insurance Fraud is a large problem for the insurance industry today. It is estimated that 10-12% of all insurance cases in Denmark involve fraudulent claims. New detection methods and IT systems play an essential role in the fight against insurance fraud.
Using HUGIN software every insurance company can develop and integrate a fraud prediction model that quantifies the risk that a claim is fraudulent even in cases where data is missing or incomplete. With compelling financial benefits as a result.
Below you will find a simple illustration of the HUGIN Fraud Prediction solution.
HUGIN software is an advanced tool for model-based decision support. It can be used to compute the probability of events such as fraud even when customer information is incomplete. A central component in a model-based decision support system is the model. A fraud detection model specifies the dependence relations between a fraudulent claim and fraud indicators and risk characteristics, including customer behavior and customer characteristics.
In particular, a fraud detection model specifies which behavior and customer characteristics differentiate fraudulent claims from legitimate claims. In the example, the traffic light allows the claims handler to classify cases as fast track, regular track, or as cases requiring additional consideration or investigation. This type of system enables insurance companies to detect fraudulent claims at an early stage, giving them more time to investigate cases with a high probability of fraud.
Exploiting advanced model-based decision support in claims handling improves the ability to identify both high risk claims and claims for fast track handling with improved results for the company: identifying high-risk claims reduces costs, identifying low risk claims saves man-time hours and increases customer satisfaction.
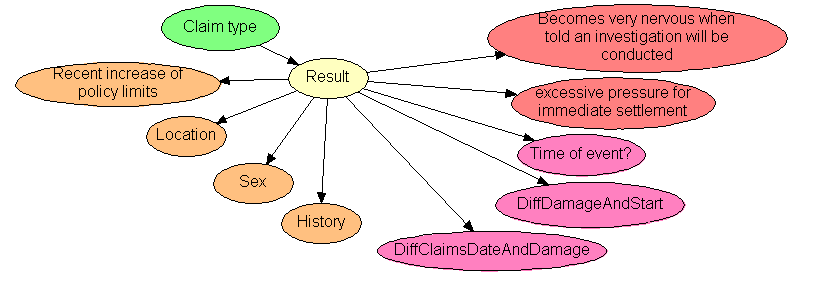
The figure above illustrates a simple fraud prediction model. The model describes dependence relations between claim type, fraud, claim history, age, etc. Even with limited information the model can assess the probability of fraud.
Claim type
Type of claim:
Claim data
Time of event:
Difference between damage and policy start:
Difference between claim date and damage date:
Policy data
Gender:
Claims history:
Residence:
Recent policy increase:
Claims handler observations
Does claimant appear nervous:
Pressure for immediate settlement:
Probability of fraud and traffic light
Using the web form above we can efficiently and in real time compute the probability of fraud with partial information on the claim. The probability of fraud is displayed as a traffic light. The color of the traffic light may change as information is being entered. Try to enter the information that a person with a history of 2 or more claims reports who pressure for immediate settlement (the traffic light turns yellow). Subsequently enter the information that the policy was increased recently. This turns the traffic light red.